
Introduction
Today’s LLMs have already ingested basically all of the publicly available information they can to build their models. In order to improve further, they’re going to need to seek out additional sources of information. One obvious such source is the countless interactions they have with their users, and while privacy concerns are certainly relevant here, for the purposes of this article I want to focus on another issue: quality signals. How will these LLMs know whether a given exchange led to a solution (defined however the user would define it)? Without this knowledge, there’s no way for LLMs to give more weight to answers that ultimately were fruitful over answers that were useless but the user gave up and ended the session.
Forums and Stack Overflow
Some of you reading this are old enough to remember the days before Stack Overflow. Back then, when you had a problem, you’d put the error message or some other details into Google and hope that someone else had run into the problem before. Unfortunately, forums were the main way such questions and answers were surfaced on the web. This meant that even if you were lucky enough to find a relevant forum thread, often you would have to scroll through many many replies to see if anyone had, in fact, solved the problem. Sometimes all you’d find is the original poster noting they’d found the answer, but cruelly declining to share what that answer was.

Whether or not a given thread had an acceptable solution was not something that was captured or surfaced in any way, which led to this problem and inefficiency. One of the things Stack Overflow got right was allowing and incentivizing question askers to mark a particular answer as the one that had solved their problem.
With this one change, the efficiency with which answers could be found - and provided - increased dramatically. Experts looking for questions to answer could easily filter out already-answered questions. Folks seeking answers could quickly jump to the ones that were most likely to work - because they’d already worked for someone else with a similar problem. This one feature, combined with gamification around it, was largely responsible for Stack Overflow’s usefulness and popularity.
This feature also made Stack Overflow’s data a gold mine for AI companies, who took advantage of Stack Overflow’s open data policies (and, later, paid for that access) to train their models on years of historic question-and-answer data. But unfortunately the rise of LLM tools (and other factors) has led to the death of Stack Overflow.
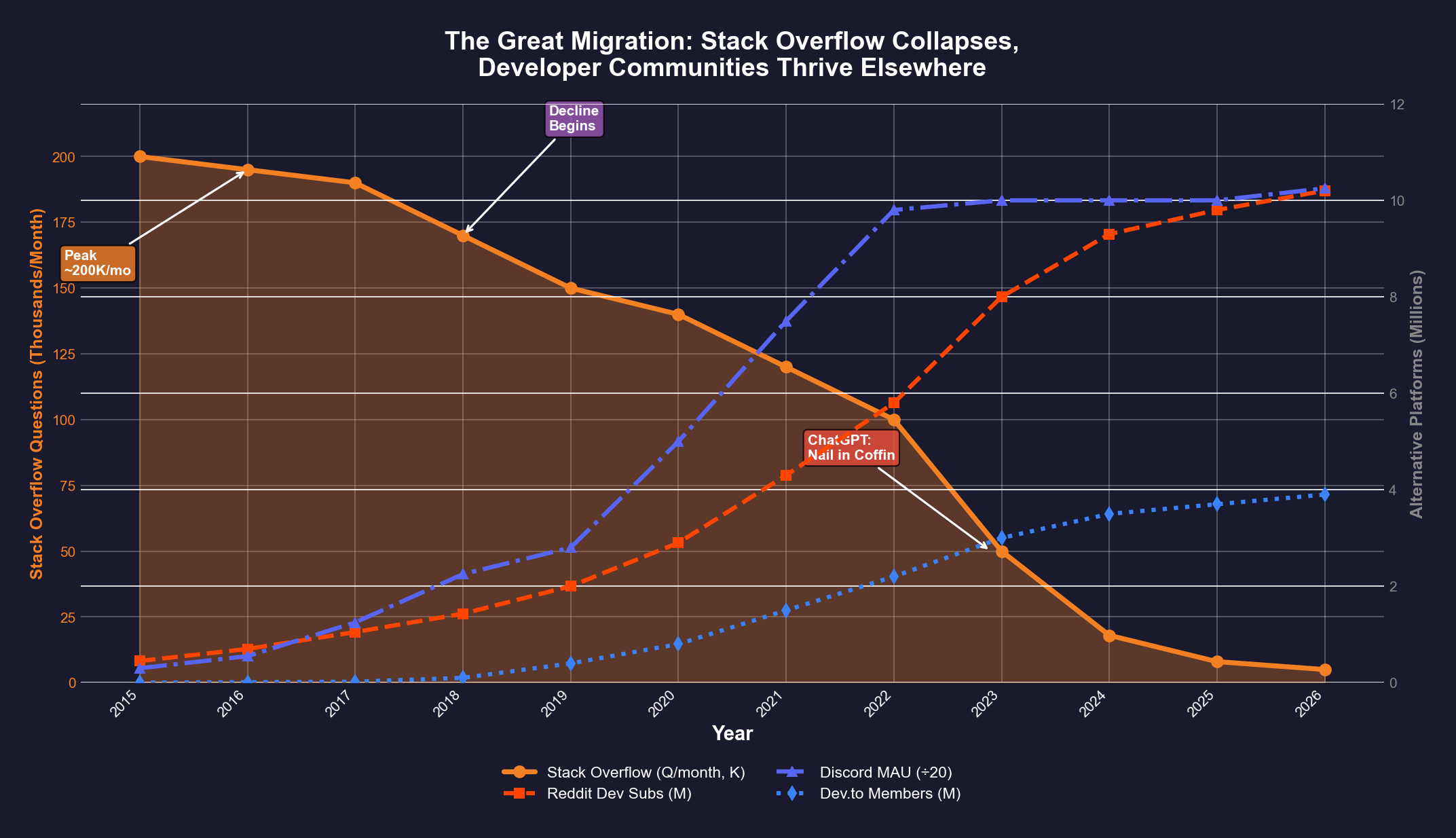
Without millions of new questions and answers to train on, where will AI models get the data they so desperately need to provide relevant, useful responses?
A New Source of Data
As the image above shows, some of the reason for Stack Overflow’s drop in popularity may be attributed to shifts to other communities. I have no doubt that AI companies are already working with these communities, either directly or surrepticiously. But the other obvious source of data to mine is the AI companies’ own users’ conversations with the companies’ existing models. There is a LOT of data there, with OpenAI’s ChatGPT claiming 2.5B requests/day from 330M US-based users in July 2025, and more recently claiming over 800M weekly active users in Feb 2026. These stored conversations are a truly massive amount of mostly text data, but they suffer from the same problem that early forums did: what was the result?
Think about your own interactions with AI chatbots. You ask a question, it provides a response. Sometimes it’s useful, sometimes it’s not. A longer conversation might have you rephrasing your original prompt, adding context, clarifying. Or maybe asking something completely unrelated in the same conversation because why not? It’s not like there’s some forum moderator who’s going to step in and tell you it’s “off-topic” - the LLM will happily answer any prompt you give it.
Now imagine you’re tasked with determining which answers the LLM gave that were most useful, and which the user found unhelpful at best. Sure, sometimes users will do you a favor and say “Thanks, that worked!” or “No, that’s not what I wanted.” But more often, they’re going to just close the session or ask another question regardless of whether they’re moving on because the interaction was a success or they’ve simply given up.
Did This Work?
For these reasons, it’s going to be imperative in the near future, I predict, for LLM agents to actively solicit from users whether the answer they provided was helpful. Obviously some user interfaces already do some A/B testing to see which kind of response a user prefers, but typically the meat of such responses is the same in either case. Asking explicitly whether a given response or conversation led to a successful solution to the original problem that was posed is the $10 Trillion question. It’s what will allow models to continue to improve over time, rather than degrading into the forums of yesteryear.
Conclusion
AI agents will need to train on their conversations with users in order to continue to learn. However, doing so without explicit data indicating whether or not a given response solved a given problem will make it very difficult to determine which responses to weight higher than others. Adding a mechanism similar to Stack Overflow’s “mark as answer” feature to LLM interactions will provide this signal and will enable future model training to weight useful responses higher, resulting in improved model usefulness over time.